
这个故事是十大网博靠谱平台一个人工智能驱动的顾问聊天机器人的,我是基于它工作的 LangChain 和 Chainlit. 这个机器人向潜在客户询问他们在企业数据空间中的问题, 开发动态调查问卷,以便更好地了解问题. 在收集了用户问题的足够信息后,它给出了解决问题的建议. Whilst formulating questions it also tries to check if the user is confused 和 needs some questions answered. 如果是这种情况,它会尝试回复它.
聊天机器人是围绕与人工智能治理相关主题的知识库构建的, 安全, 数据质量, 等. 但你也可以选择其他话题.
该知识库存储在矢量数据库(做),并在每个步骤中用于提出问题或提供建议.
然而,这个聊天机器人可以基于任何知识库,并在不同的环境中使用. 所以你可以把它作为其他咨询聊天机器人的蓝图.
交互流
The normal flow of a chatbot is simple: the user asks a question 和 the bot answers it 和 so on. 机器人通常会记住之前的互动,所以有一个历史记录.
然而,这个机器人的交互是不同的. 它是这样的:

人工智能驱动的顾问聊天机器人互动
在这种情况下,聊天机器人会问一个问题, 用户回答并重复这个交互几次. If the accumulated knowledge is good enough for a response or the number of questions reaches a certain threshold, 给出一个回应, 否则就会问另一个问题.
粗略的体系结构
以下是该应用程序的参与者:

主要参与者是人工智能驱动的顾问聊天机器人
我们有4个参与者:
用户
The application which orchestrates the workflow between ChatGPT, the knowledge base 和 the user.
ChatGPT 4 (gpt-4-0613)
知识库(采用矢量数据库) 做)
我们已经尝试了ChatGPT 3.但结果不是很好,很难产生有意义的问题. ChatGPT 4 (gpt-4-0613) seemed to produce much better questions 和 advices 和 be more stable too.
我们还试验了最新的ChatGPT 4模型(gpt-4 - 1106预览版), GPT 4 Turbo), 但是我们经常从OpenAI函数调用中遇到意想不到的结果. 所以我们经常会看到这样的错误日志:
文件“pydantic /主要.Py ",第341行,pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError:响应标签的2个验证错误
extracted_questions
必需的字段(type=value_error).失踪)
questions_related_to_data_analytics
必需的字段(type=value_error).失踪)
工作流-它是如何工作的
下图显示了该工具的内部工作原理:

聊天机器人工作流
以下是工作流程的步骤:
该工具向用户询问一个预定义的问题. 这是典型的:”
在你的数据生态系统中,你最关心的是哪个领域?”用户回答最初的问题
聊天机器人检查用户的回复是否包含一个合法的问题.e. 一个不离题的问题)
-如果是,则启动一个简单的查询代理来澄清问题. 这个简单的代理使用ChatGPT 4和DuckDuckGo搜索引擎.现在聊天机器人决定是提出更多的问题还是给出建议. 这个决定受到一个简单规则的影响:如果问题少于4个, 还有一个问题, otherwise we let ChatGPT decide whether it can give advice or continue 与 the questions.
-如果决定继续问问题, the vector database 与 the knowledge base is queried to retrieve the most similar texts to the user’s answer. The vector database search result is packed 与 the questions 和 answers 和 sent to ChatGPT 4 for it to generate more questions.
- If the decision is to give advice, the knowledge base is queried 与 all questions 和 answers. The most similar parts of the knowledge base are extracted 和 together 与 the whole questionnaire (questions 和 answers) included in the advice generating prompt to ChatGPT. 给出建议后,流程终止.
实现
整个实现可以在这个存储库中找到:
GitHub - onepointconsulting/ Data - Questionnaire - 代理:数据问卷代理聊天机器人
The installation instructions for the project can be found in the README file of the project:
http://github.com/onepointconsulting/data-questionnaire-agent/blob/main/README.md
应用程序模块
The bot contains a service module where you can find all of the services that interact 与 ChatGPT 4 和 perform certain operations, 比如生成PDF报告和向用户发送电子邮件.
服务
这是包含服务的文件夹:
最重要的服务是:
咨询服务 -创建Langchain LLMChain 用于生成建议. LLMChain使用 OpenAI功能,就像这个应用程序中的大多数链一样. 此函数的输出模式在 openai_schema.py文件.
嵌入服务 -创建 OpenAI based embeddings from the knowledge base which should be a list of text documents.
html发电机 -用于生成email和PDF格式的HTML函数
邮件发送者 -用来发送电子邮件.
问题生成服务 -用于生成除第一个生成的问题外的所有问题. 它还使用了Langchain LLMChain 与 OpenAI功能.
相似性搜索 - used使用 做. The most interesting function is the similarity_search function which performs the search multiple times to maximize up to a limit the number of tokens to send to ChatGPT 4
标签服务 -用来判断用户在回答问题时是否有合法的问题. 在这项服务中,我们使用的是LangChain的 create_tagging_chain_pydantic 方法生成标记链.
数据结构
在这个应用程序中有一个数据结构模块:
在这种情况下,我们有两个模块:
用户界面
这是一个模块 Chainlit 基于用户界面代码:
http://github.com/onepointconsulting/data-questionnaire-agent/tree/main/data_questionnaire_agent/ui
该文件用主实现的 Chainlit 用户界面为:
data_questionnaire_chainlit.py. 它包含应用程序的主要入口点以及运行代理的逻辑.
The method in this file which contains the implementation of the workflow is process_questionnaire.
十大网博靠谱平台UI的注意事项
Chainlit版本是从版本0派生出来的.7.0和修改以满足给我们的一些要求. 该项目应该工作,但使用更现代的Chainlit版本.
提示
我们将提示符从Python代码中分离出来,并使用 toml 存档:
http://github.com/onepointconsulting/data-questionnaire-agent/blob/main/prompts.toml
The prompts use delimiters to separate que instructions from the knowledge base 和 the questions 和 answers. 与ChatGPT 3不同,ChatGPT 4似乎能够很好地理解分隔符.5,这很容易混淆. 下面是一个用于生成问题的提示符的例子:
(问卷调查)
(调查问卷.最初的)
在你的数据生态系统中,你最关心的是哪个领域?"
system_message = "You are a data integration 和 gouvernance expert that can ask questions about data integration 和 gouvernance to help a customer 与 data integration 和 gouvernance problems"
human_message = """Based on the best practices 和 knowledge base 和 on an answer to a question answered by a customer, \
please generate {questions_per_batch} questions that are helpful to this customer to solve data integration 和 gouvernance issues.
The best practices section starts 与 ==== BEST PRACTICES START ==== 和 ends 与 ==== BEST PRACTICES END ====.
The knowledge base section starts 与 ====知识库启动==== 和 ends 与 ====知识库端====.
The question asked to the user starts 与 ====问题==== 和 ends 与 ====问题结束====.
用户 answer provided by the customer starts 与 ====回答==== 和 ends 与 ====回答结束====.
====知识库启动====
{knowledge_base}
====知识库端====
====问题====
{问题}
====问题结束====
====回答====
{答案}
====回答结束====
"""
(调查问卷.二次)
system_message = "You are a British data integration 和 gouvernance expert that can ask questions about data integration 和 gouvernance to help a customer 与 data integration 和 gouvernance problems"
human_message = """Based on the best practices 和 knowledge base 和 answers to multiple questions answered by a customer, \
please generate {questions_per_batch} questions that are helpful to this customer to solve data integration, 治理和质量问题.
The knowledge base section starts 与 ====知识库启动==== 和 ends 与 ====知识库端====.
The questions 和 answers section answered by the customer starts 与 ====问卷==== 和 ends 与 ====问卷结束====.
用户 answers are in the section that starts 与 ====回答==== 和 ends 与 ====答案结束====.
====知识库启动====
{knowledge_base}
====知识库端====
====问卷====
{questions_answers}
====问卷结束====
====回答====
{答案}
====答案结束====
"""
如您所见,我们正在使用分隔符部分,如e.g: ====知识库开始====或====知识库结束====
外卖
我们尝试使用ChatGPT 3构建有意义的交互.5, 但是这个模型不能很好地理解提示分隔符, whereas ChatGPT 4 (gpt-4-0613) could do this 和 allowed us to have meaningful interactions 与 users. 因此,我们为这个应用程序选择了ChatGPT 4.
就像我们之前提到的, 我们尝试用gpt-4 - 1106预览版替换gpt-4-0613, 但结果并不好. 函数调用经常失败.
When we started the project we had a limit of 10000 tokens per minute 和 this was causing some annoying errors. But now OpenAI has increased the limits to 300K tokens 和 that increased the app’s stability:
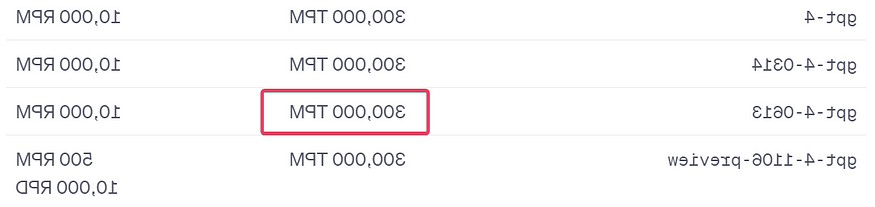
增加了每分钟令牌的限制
The other big takeaway is that you need to be really careful about limiting the scope of interaction, 否则你的机器人可能会被误用, 就像这个例子:

离题问题
But we found a way to prevent it 和 the bot can recognize off topic questions (see [tagging] section in promps.toml 文件):

The final takeaway is that ChatGPT4 is up to this challenge of generating a meaningful consultant-like interaction in which it can generate an open-ended questionnaire that ends 与 a series of meaningful advice.








